Qwen2.5-Omni
🔗 연관 포스트
- Qwen3-Omni: 예정
📌 이 논문을 읽은 이유
Qwen3-Omni를 이해하기 위해 읽게 되었다.
기존에도 텍스트-이미지, 텍스트-오디오 등 두 가지 모달을 함께 사용하는 모델들은 많았지만, 네 가지 모달을 동시에 사용하면서도 높은 성능을 보이는 모델은 드물었다.
오디오 AI 연구를 진행하면서 언어적 특성과 음성적 특성을 함께 이해할 수 있는 모델의 필요성을 자주 느꼈다. 음성에는 텍스트 요소와 반언어적 요소가 함께 존재하며, 그중 하나만 사용했을 때는 성능적 한계가 분명해 보였기 때문이다.
이 논문은 LLM 기반으로 하면서 음성부터 영상까지 지원하고, 실시간으로 응답을 생성하는 점이 특히 인상 깊었다.
💡 논문의 주요 내용 간단 요약
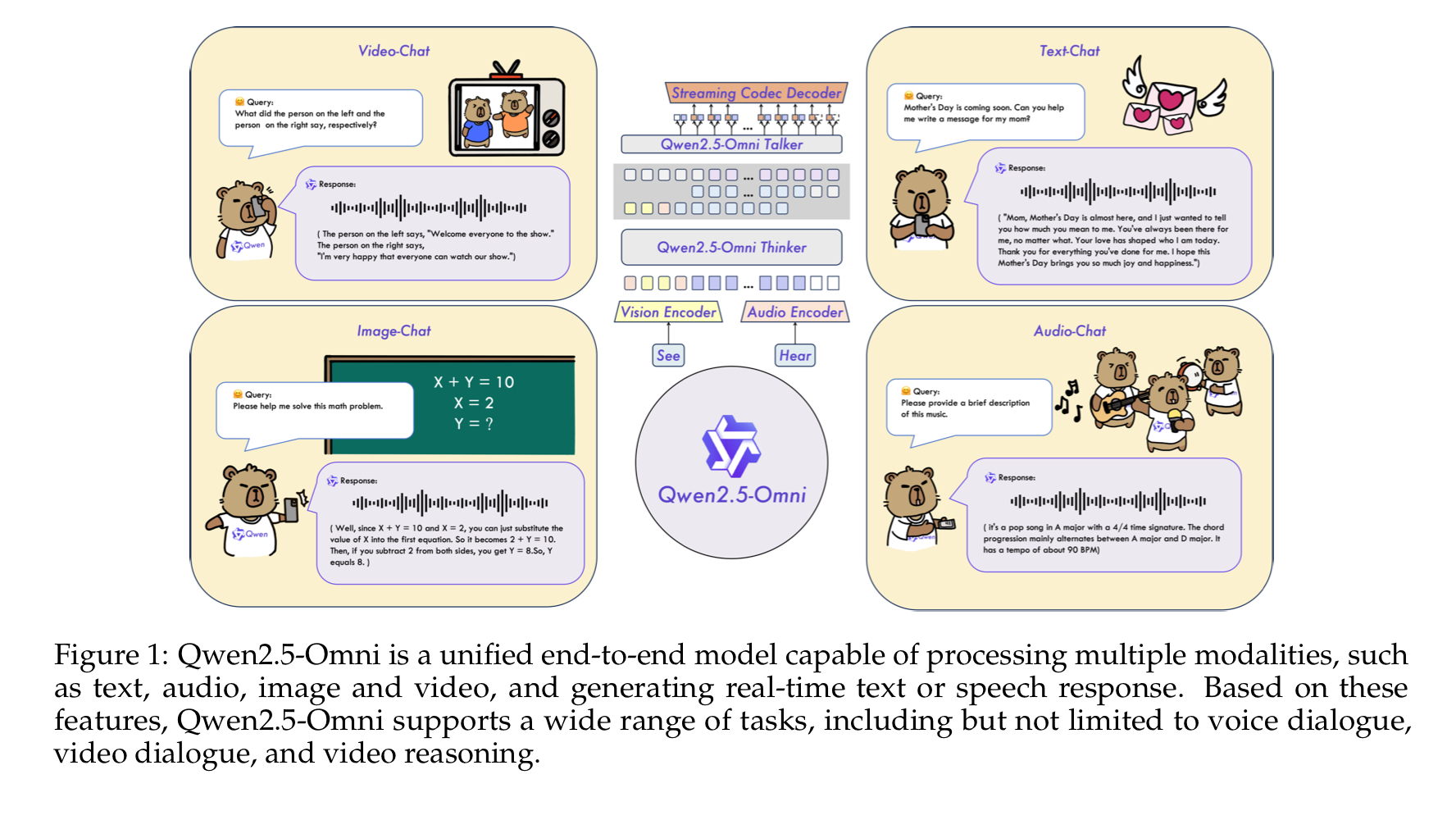
Qwen2.5-Omni는?
- 텍스트, 오디오, 이미지, 영상을 입력 받아, 이에 대한 응답을 실시간 텍스트와 음성으로 생성하는 멀티모달 모델
- 뇌처럼 생각하고, 입처럼 대답하는 Thinker-Talker 구조 사용
- 오디오와 영상의 시계열 요소를 고려하기 위해, TMRoPE(Time-aligned Multimodal RoPE)라는 새로운 positional embedding 방법 제안
📚 핵심 아이디어와 주요 기법 정리
Thinker-Talker 구조
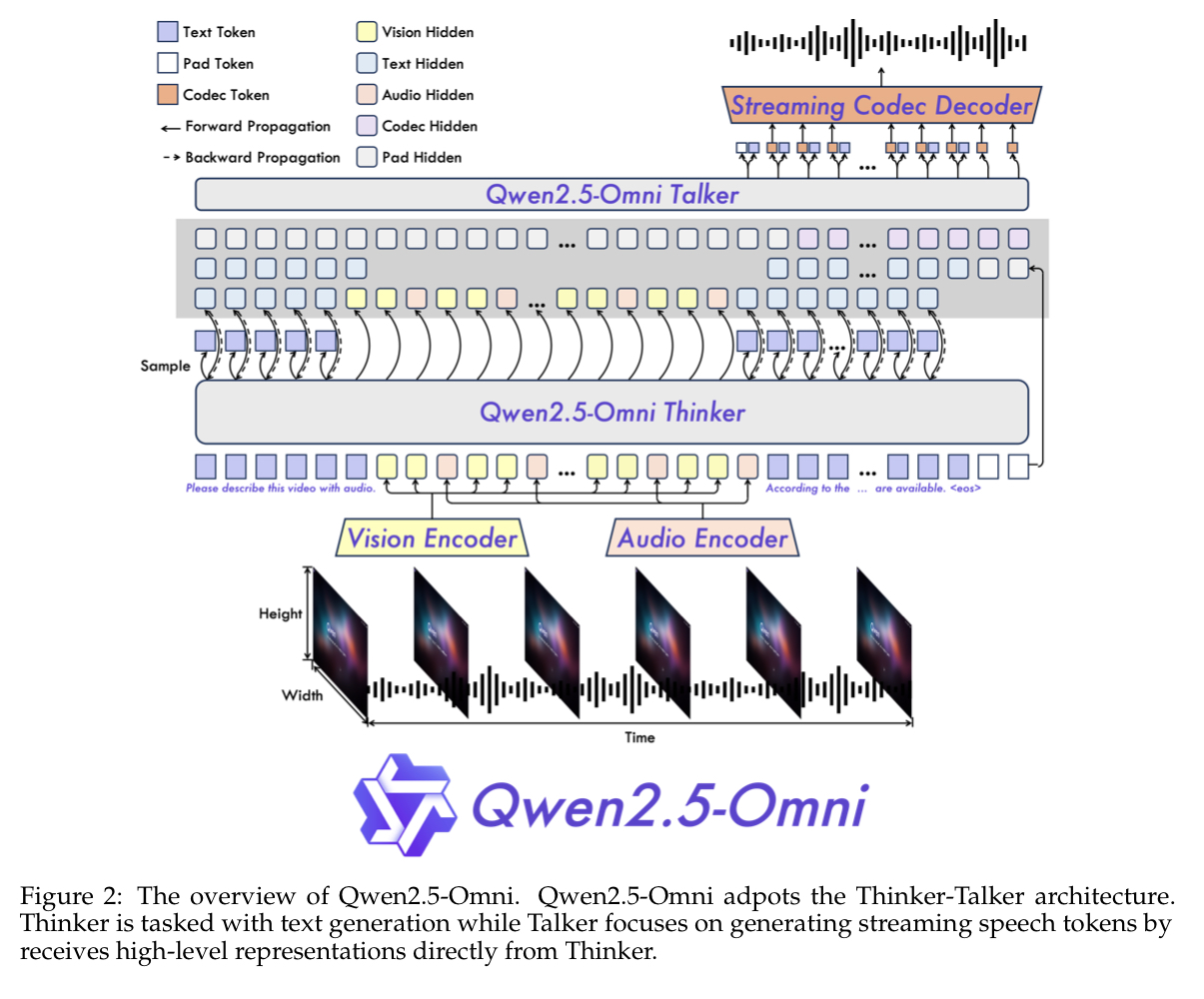
Thinker
- 사람의 “뇌”처럼 입력 값을 이해 $\rightarrow$ high-level representation과 관련된 텍스트 생성
- 입력값은 텍스트, 오디오, 이미지, 영상을 지원
- 오디오 encoder + 이미지 encoder + Transformer decoder 구조
Talker
- 사람의 “입”처럼 음성을 생성하는 부분
- Thinker의 high-level representation과 텍스트 token을 스트리밍 방식으로 입력받고 $\rightarrow$ 이산적인 음성 token을 출력
- 이중 트랙(dual-track) autoregressive Transformer decoder 구조
어떻게 다양한 모달을 입력 받을까? Perceivation!
다양한 입력값
- 텍스트: byte-level byte-pair encoding하는 Qwen tokenizer 사용
- 오디오: 16 kHz로 샘플링 $\rightarrow$ 128-channel Mel-Spectrogram (window size 25ms, hop size 10ms) $\rightarrow$ Qwen2-Audio encoder (각 frame이 원래 음성의 40ms와 대략적으로 일치하게 바꿈) 사용
- 비전: 이미지 & 영상 $\rightarrow$ ViT 기반인 Qwen2.5-VL 사용. 음성 sampling rate와 맞추기 위해 dynamic frame rate 사용. 이미지는 2개의 동일한 이미지로 취급하여 일관성 유지
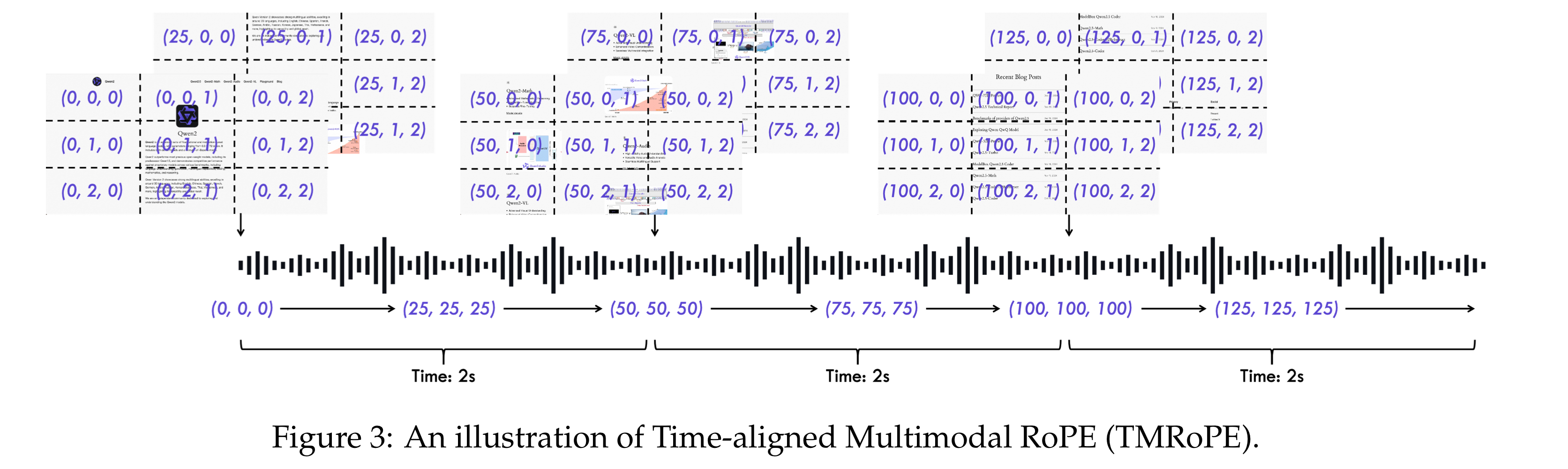
TMRoPE(Time-aligned Multimodal RoPE)
- M-RoPE(Multimodal RoPE) + 절대 시간적 위치(absolute temporal position)으로, 멀티모달의 3D 위치적 정보를 인코딩함
- rotary embedding을 3가지 요소로 분해 $\Rightarrow$ temporal, height, width
- 텍스트: 3가지 요소 모두 동일한 positionID 값 사용
- 오디오: 40ms를 기준으로 같은 temporal ID를 사용하며, 3가지 요소에서 동일한 해당 값을 positionID으로 사용
- 이미지: temporal ID는 상수로 변하지 않지만, 이미지의 height와 width에 다른 ID 적용
- 비디오: 음성처럼 40ms를 기준으로 같은 temporal ID를 사용하며, 이미지처럼 height와 width에 다른 ID 적용함
- 멀티모달 입력이 들어올 경우, 각 positional 숫자는 이전의 모달의 마지막 숫자에서 1을 더한 값을 사용함. 즉, 연속된 positional 값을 사용하게 됨.
- positional 값을 할당한 후에는 representation을 재정렬하게 됨. 이를 time-interleaving 방법이라고 칭하기로 함.
- 2초마다 자른 비디오와 음성을, visual - 오디오 순서로 번갈아 하며 배열함
생성
텍스트
- Thinker에서 바로 생성됨
- LLM과 동일하게 생성됨
음성
- Thinker에서 생성된 high-level representation + text token embedding $\rightarrow$ Talker가 받아서 사용
- high-level representation: streaming 방식이기 때문에, 미리 어떤 tone의 음성을 만들어야 알아야하기 때문에 해당 값을 받아옴. 하지만 해당 값은 representational space에서 사전적인 유사도가 비슷한 값끼리 뭉쳐있음. 음성을 생성할 시에 전혀 다른 단어를 생성할 여지가 있음.
- text token embedding: 정확한 단어를 사용하기 위해 텍스트 정보를 함께 입력해줌
- (ex) cat 입력 $\Rightarrow$ high-level representation만 사용했을 때 “kitten”이라는 음성이 생성될 수 있음. 이를 방지하기 위해 text token embedding 사용
- 더 효율적인 speech codec인 qwen-tts-tokenizer
- 음성에서 중요한 정보를 추출하고, 스트리밍 방식으로 음성으로 decoding이 가능함
- Talker는 오디오와 텍스트 token을 autoregressive하게 생성하는데, 음성을 생성할 때 word나 timestamp-level 정렬(alignment)가 필요가 없음 $\Rightarrow$ 학습과 추론 단계가 간단해짐
스트리밍
Prefilling
- 시간(temporal) 차원을 따라 block-wise attention을 지원
- audio encoder: 전체에 대한 full attention 대신 2초 block 내에서의 attention 수행
- vision encoder: 학습에는 flash attention 사용. 추론에는 2x2 token을 하나의 token으로 바꿔주는 MLP 레이어 사용. patch 크기는 14로 다양한 해상도 지원
스트리밍 Codec 생성
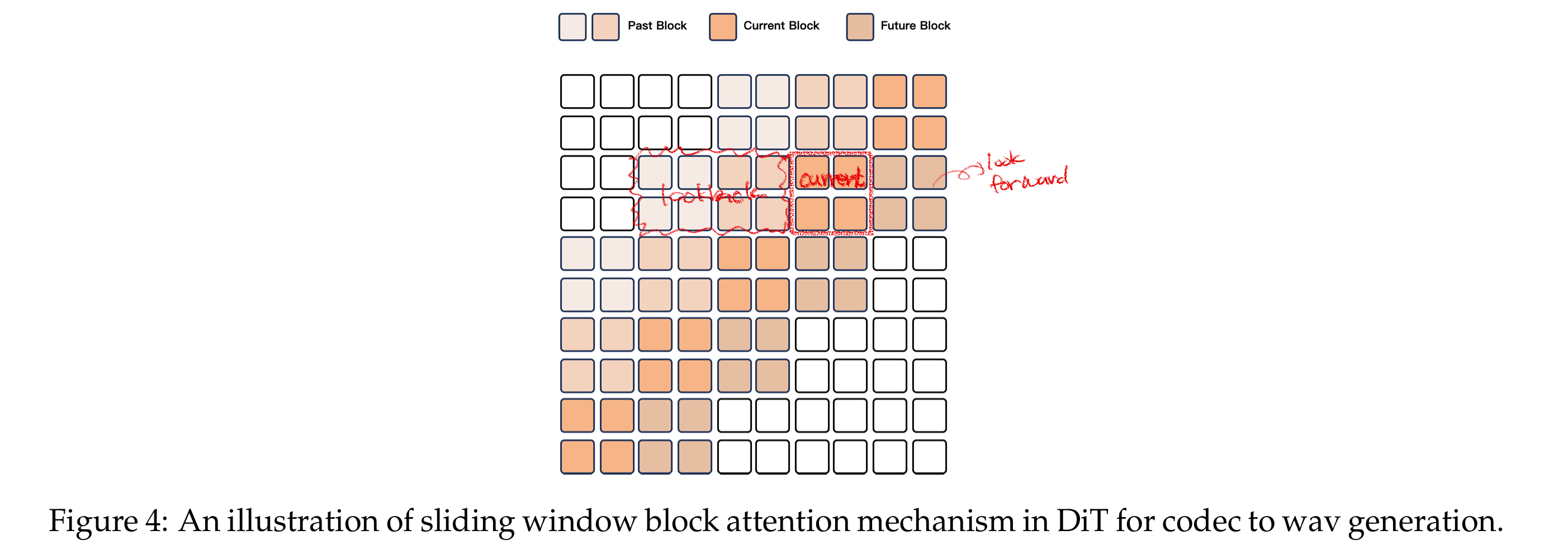
- 음성 생성 과정: code $-\text{Flow-Matching}\rightarrow$ mel-spectorgram $-\text{BigVGAN}\rightarrow$ waveform
- sliding window block attention으로 오디오 스트리밍 지원
- 인접한 code를 block으로 만들고 이를 attention mask로 사용
- 해당 논문에서는 DiT의 reception field를 4 block으로 설정하여, lookback 2개, lookahead 1개 사용
- 각 code와 관련 block들을 함께 넣어주어 Flow-Matching 방법으로 mel-spectrum 조각을 만들고, 해당 조각을 BigVGAN을 통해 waveform 생성
Pre-training
- LLM 고정하고 audio와 vision encoder 각각 학습. 각각 audio-text, image-text 데이터 사용
- LLM도 같이 학습. 최대 길이는 8192 token인 다양한 multimodal 데이터 사용
- 긴 데이터에 대한 성능 향상을 위해 sequence 길이가 32k인 데이터 사용해서
Post-training
Thinker
- 위의 CHatML 데이터셋 포멧 데이터를 사용해서 post-training 진행
- text 기반 대화 데이터, 음성 모달 대화 데이터, 오디오 모달 대화 데이터, 모달이 혼합된 데이터 사용
Talker
- 맥락적 연속성(context continuation) 학습
- In-Context Learning(ICL) 학습 단계에서 텍스트 supervised + 음성에서 다음 token 예측 수행
- semantic한 특징을 음성에 monotonic하게 mapping
- prosody, emotion, accent와 같은 맥락에 적합한 다양한 특징을 생성할 수 있게 함
- timbre를 음성에서 분리하는 기법도 사용해서 특정 목소리와 infrequent한 텍스트 특성을 무시할 수 있게함
- DPO로 음성 생성 안전성 확보
- 이미지
- reinforcement learning 단계를 도입하여 음성 생성에서의 안정성 확보
- 데이터셋을 $(x, y_w, y_l)$로 구성
- $x$: input 음성과 텍스트
- $y_w$: 잘 생성된 음성
- $y_l$: 잘못 생성된 음성
- word-error rate(WER)과 puctuation pause error rate를 score로 사용해서 rank 진행
-
speaker fine-tuning 잔행하여, 특정한 목소리를 적용할 수 있게 하면서 자연스러움 향상
- 음성 응답의 자연스러움과 통제성을 위해 multi-speaker instruction fine-tuning 진행
결과
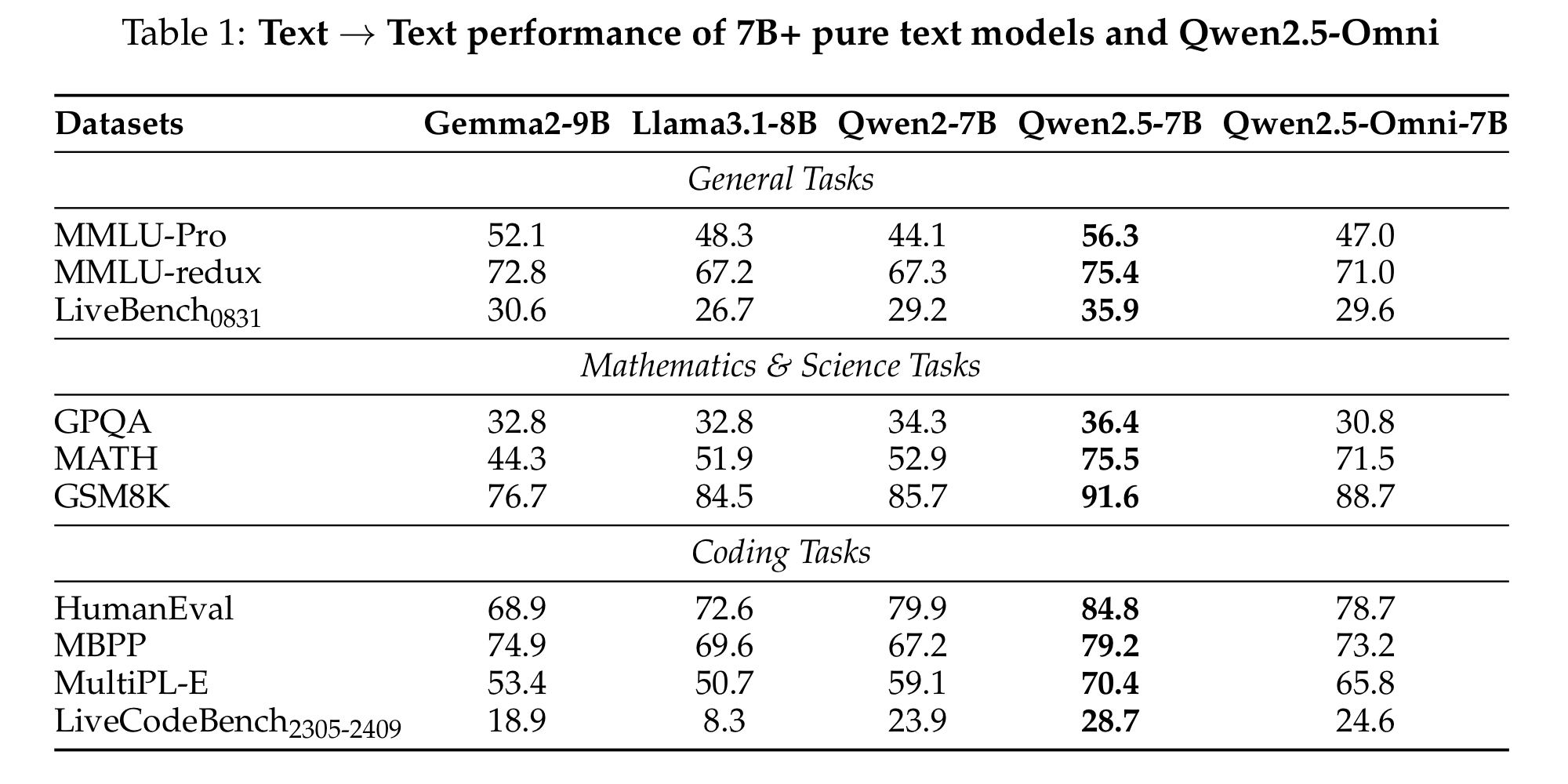
- 비슷한 크기(7B)와 비교했을 때, 성능이 대체로 Qwen2 < Qwen2.5-Omni < Qwen2.5 를 보임

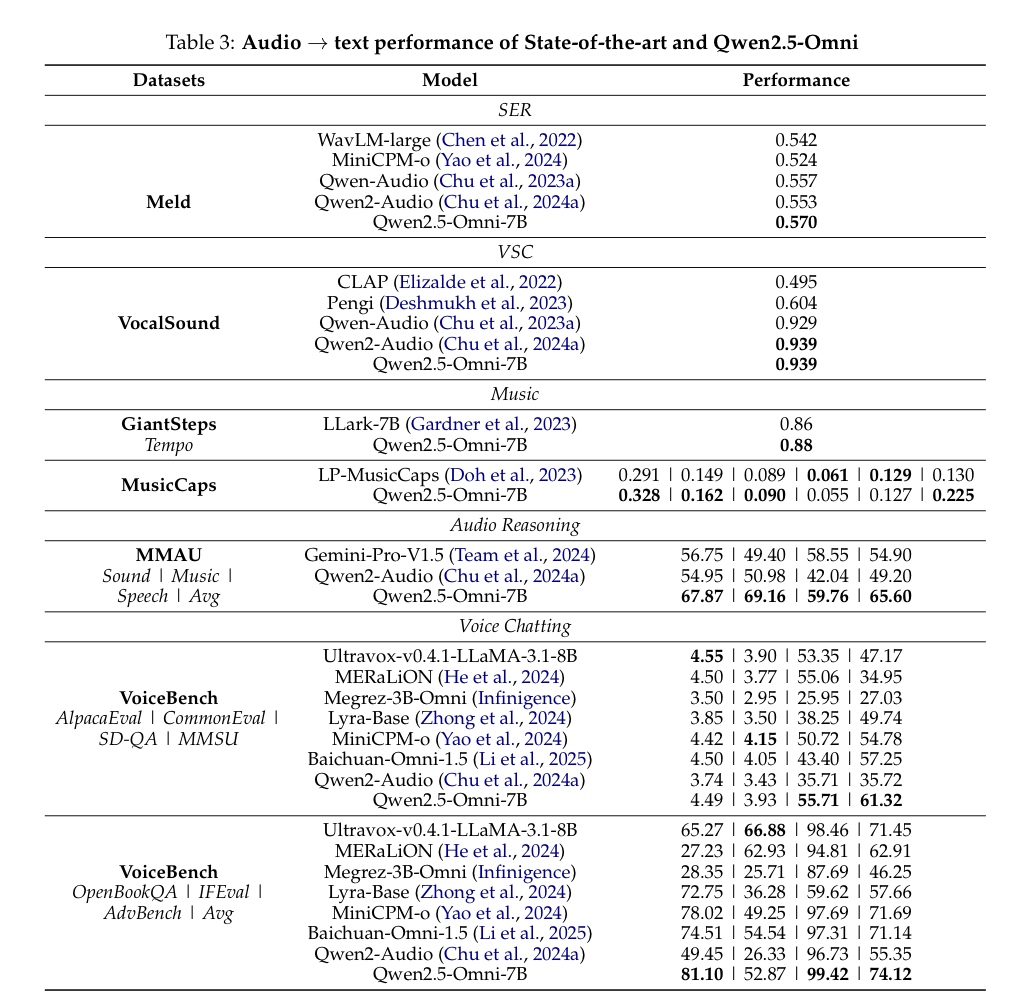
- 오디오 이해(audio understanding)에서 SOTA급 성능을 보임
- 음악, VSC(VocalSound 데이터셋), audio reasoning 같은 부분에서 좋은 성능을 보임
- VoiceBench에서 74.12점을 달성 $\rightarrow$ 음성을 사용한 상호작용에서 좋은 성능을 보임
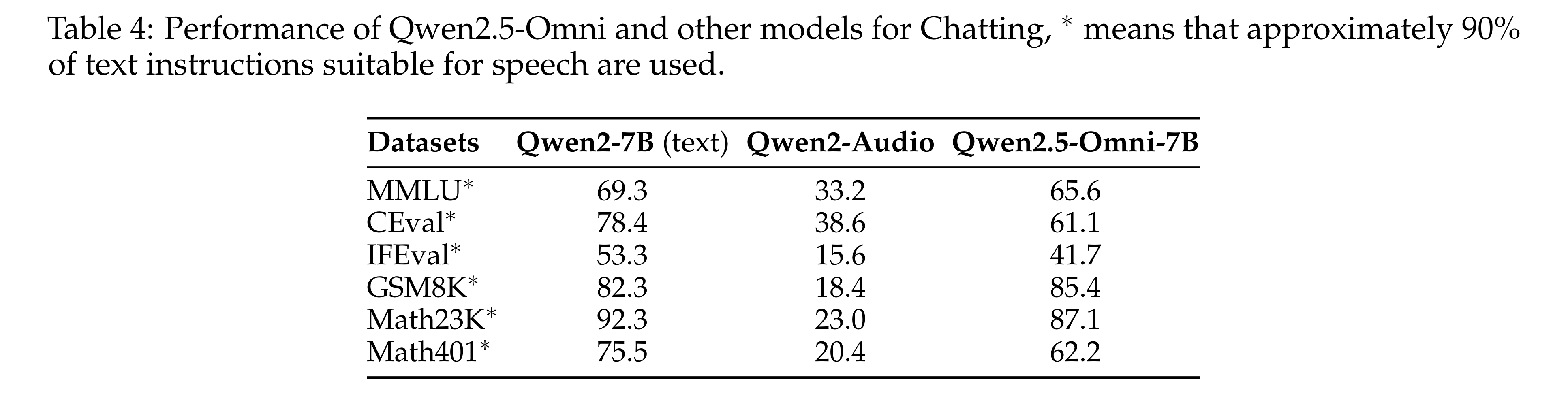
- Table 4: text instruction을 speech instruction으로 바꿔서 테스트했을 떄, Qwen2-Audio보다 Qwen2-7B에 가까운 성능을 보임. 즉, 기존 오디오 모델보다 지시사항을 명확하게 잘 이햐한 모델임을 보임
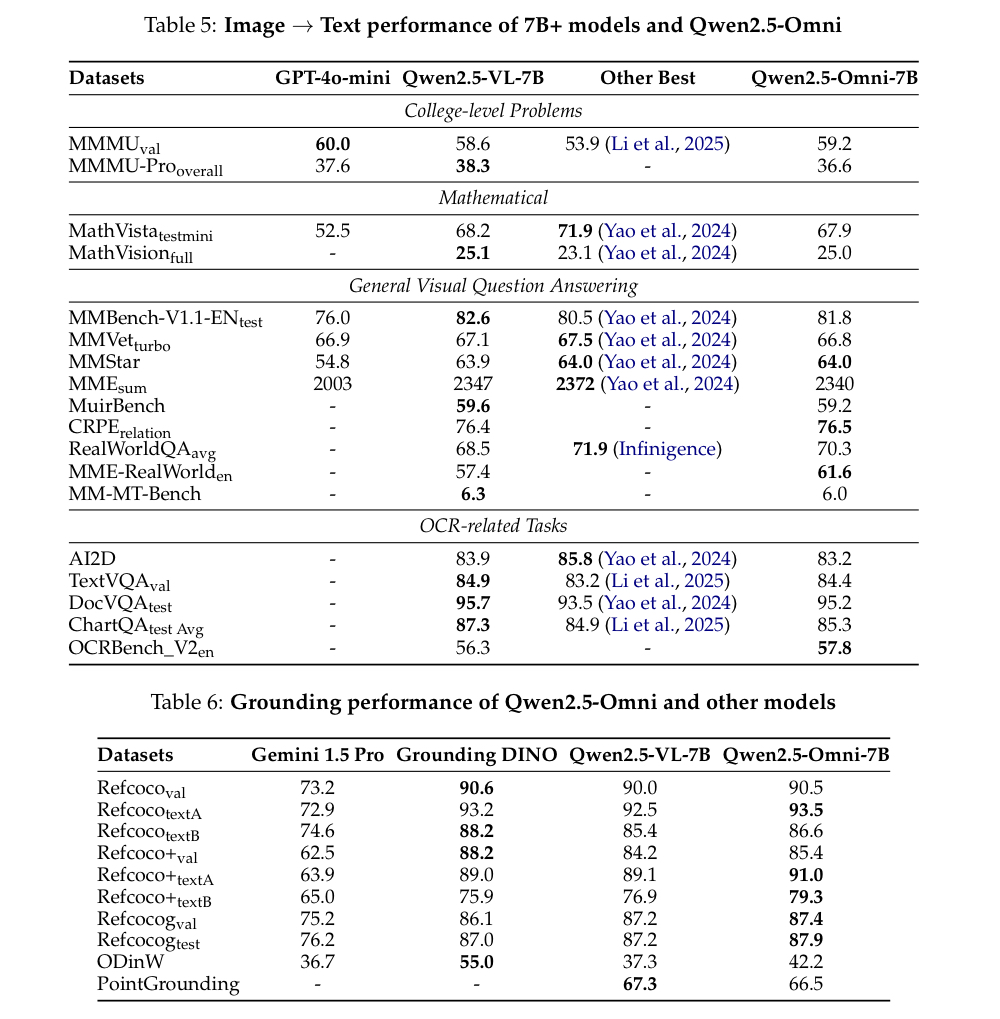
- 텍스트를 입력했을 때, 이미지에서 해당 객체를 탐지하는 grounding에서 다른 모델들보다 대체적으로 높은 성능을 보임
- 학습에 사용되지 않은 객체를 텍스트만으로 인식할 수 있는지를 평가하기 위한 ODinW(Object Detection in the Wild) 데이터셋에서 42.2mAP를 달성하며, visual grounding의 가능성을 확인함
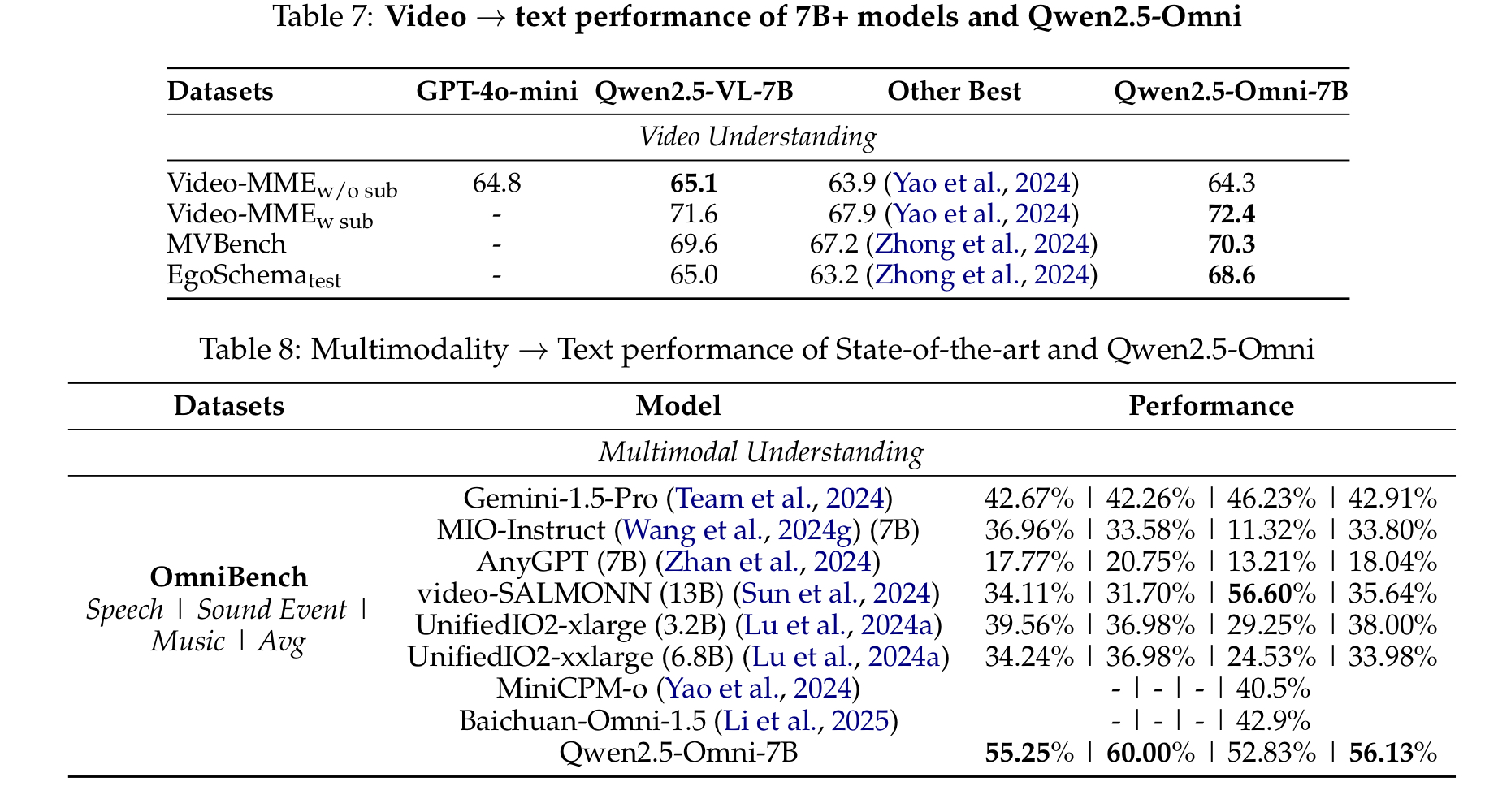
- 영상 이해도 측면에서는 전체적으로 좋은 성능을 보임
- 멀티모달 측면에서도 다른 모델들보다 훨씬 좋은 성능을 보이고 있음
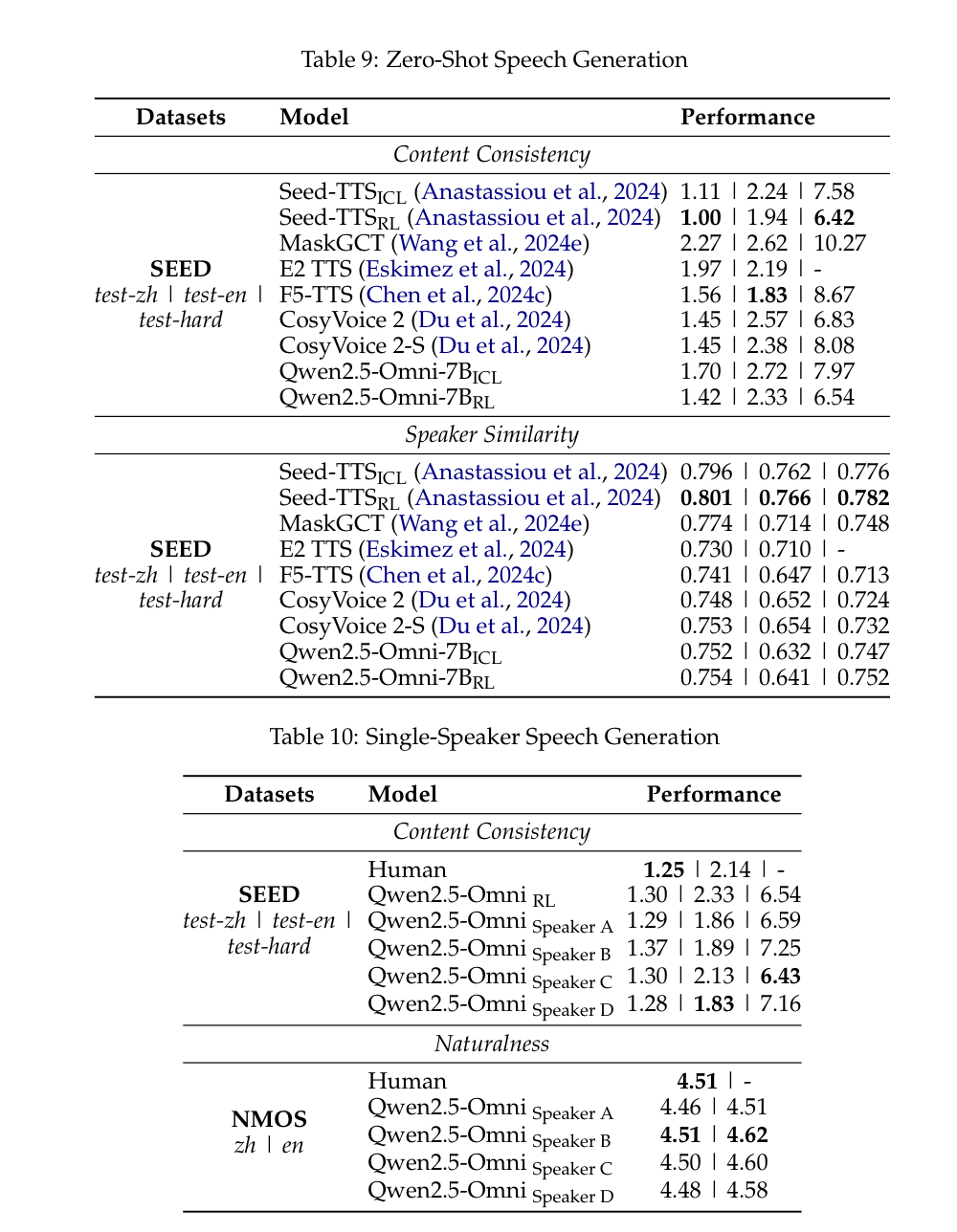
- 새로운 화자에 대해서 학습하지 않는 zero-shot TTS에서 In-context learning(ICL)으로 상당히 좋은 결과를 보임
- 하지만, 강화 학습(RL) 이후 더 좋은 성능을 보임. 즉, attention misalingmnet, 발음 오류, 부자연스러운 멈춤(pause)에 대해 개선됨.
- Table 10: Speaker fine-tuning 후의 결과의 성능이 더 좋았음.
🔍 개인적인 생각
Attention 범위를 제한함으로써 실시간 처리가 가능하다는 점이 인상 깊었다. 전체 Attention과 부분 Attention을 모두 지원하는 모델이 등장한다면, 성능 면에서 어떤 차이를 보일지 궁금하다.
또한, 생성할 오디오에 반언어적 요소를 부여하기 위해 별도의 특징값을 추가한 부분이 매우 흥미로웠다.
BERT의 [CLS] 토큰처럼 의미를 제어하는 핵심 포인트 역할을 보는 것 같았다.
최근 연구들을 보면, 역시 오디오 생성에 LLM의 결합이 성능 향상의 핵심인 건 확실한 것 같다.
다만 멀티모달 구조는 모델 크기가 커지기 때문에, 실제 활용에는 여전히 의문이 든다. 향후 Quantization 등으로 모델을 경량화했을 때, 대형 멀티모달 모델과 비교하여 어느 정도의 정확도를 유지할 수 있을지가 중요한 연구 방향이 될 것으로 보인다.
댓글남기기